
Dlaczego nie ma mojej strony w Google? To pytanie zadaje sobie wielu właścicieli stron, którym zależy na obecności w wynikach wyszukiwania. Większość właścicieli stron www chce, aby ich strona była widoczna w wyszukiwarce. Zdarza się jednak, że zamiast upragnionej, wysokiej pozycji – stwierdzasz, że w wyszukiwarce w ogóle nie istniejesz! Co wtedy? Gdzie szukać ratunku?
Z tego wpisu dowiesz się:
- Jak ustawienia w robots.txt powodują, że w Google nie widać Twojej strony?
- Czy metatagi mogą powodować, że Google nie widzi Twojej strony?
- Jak zabezpieczenia hasłem wpływają na widoczność stron w wyszukiwarce?
- Dlaczego strony nie widać w Google przy pewnych ustawieniach serwera?
- O co chodzi z kodami odpowiedzi HTTP?
Zanim jednak zaczniesz czytać dalej – ustalmy jedno. Ten artykuł daje wskazówki na temat temat sytuacji pod tytułem: dlaczego nie ma mojej strony w Google. Oznacza to, że jej tam naprawdę nie ma, że nie jest zaindeksowana, nie wyświetla się na żadnym miejscu. Trzeba rozróżnić tę sytuację od tego, że strona pojawia się na miejscu numer 86, gdzie nikt jej nie widzi. W tym drugim wypadku Twoja strona „jest w Google”, tylko wyszukiwarka uznała, że inne strony są bardziej wartościowe i wyświetla je wyżej. Rozumiem zatem, że Twojej strony na serio nie ma w Google. Zgadza się? To jesteś we właściwym miejscu!
1. Ustawienia w pliku Robots.txt
Według wskazówek Google każda z domen internetowych powinna zawierać plik robots.txt w swoim głównym katalogu. Plik ten jest definicją katalogów, które chcemy lub których nie chcemy indeksować w zasobach wyszukiwarek internetowych. Dyrektywy te czytane są przez Google oraz inne popularne wyszukiwarki (jak BING).
Popularna dyrektywa disallow pozwala na wykluczenie z indeksowania zarówno plików, jak i katalogów. W prosty sposób możemy zablokować indeksację pojedynczego pliku w robots.txt:
User-agent: *
Disallow: /folder/plikdoukryciazhasłami.html
Zwróćmy uwagę na fakt, że tym sposobem – nie ukrywamy faktycznie plików, gdyż szkodliwy użytkownik – może przeczytać plik robots.txt i obejrzeć ten ukryty plik.
Cały folder z zasobów wyszukiwarki – wykluczamy w następujący sposób:
User-agent: *
Disallow: /folderu/
Drobna uwaga, której poświęcimy znacznie więcej czasu w kolejnym artykule – blokując foldery, uważajmy, by nie zawierał on skryptów JS oraz CSS. Spowodować to może kolejne problemy z wyszukiwarką Google.
2. Blokujące metatagi
Brak indeksowania Twojej strony w Google może być spowodowany obecnością blokujących metatagów. Upewnij się, że na Twojej stronie brak tego typu tagów, a jeśli je odnajdziesz – niezwłocznie je usuń.
Blokujący metatag „robots” umieszczony w nagłówku strony powoduje, że robot wyszukiwarki nie może indeksować zawartych treści oraz podążać za umieszczonymi na stronie linkami:<meta name="robots" content="noindex, nofollow">
Po umieszczeniu w nagłówku:
<meta name="robots" content="noindex, follow">
robot nadal nie będzie indeksował treści, ale będzie mógł podążać za linkami.
Pamiętaj, że nawet jeśli strona zawiera blokujące metatagi, użytkownik bez problemu zobaczy całą treść – jedynie roboty nie zaindeksują odpowiednich jej części.
3. Blokada hasłem
Jeżeli dostęp do strony internetowej lub jej części wymaga logowania, to niestety robot Google nie będzie mógł się dostać do treści chronionych hasłem. Nie będą dla niego widoczne różnego rodzaju ważne słowa kluczowe i unikatowe informacje, dlatego warto się upewnić, że dostęp do istotnych treści jest swobodny i nieograniczony.
Zauważyłeś problemy w indeksowaniu podstron Twojego portalu? Możliwe, że przeglądarka zapamiętała hasło i kiedy na nie wchodzisz logowanie następuje automatycznie – sprawdzisz to sprawdzając wyświetlanie strony poprzez tryb incognito.
W przypadku, gdy treści na stronie są przez Ciebie blokowane świadomie musisz zadbać o to, aby jak najwięcej informacji było dostępnych dla robota wyszukiwarki. Zaprojektuj strukturę danych tak, aby istotne treści znalazły się w części nie chronionej hasłem – wtedy robot bez problemu je przeczyta i zaindeksuje.
4. Blokada na poziomie serwera
Ataki sieciowe i ataki na strony internetowe mogą powodować odcięcie ruchu przez operatora hostingowego. Takie doraźne blokady powodują, że przez określony czas roboty chcące dostać się na stronę z blokowanej lokalizacji nie będą miały takiej możliwości.
Jeżeli robot Google nie może dostać się na stronę internetową to sprawdź, czy Twój operator hostingu nie nałożył tego typu blokady. Brak dostępności strony dla robota negatywnie wpływa na ocenę strony, dlatego jeśli problem trwa długo – rozważ przeniesienie strony do innego operatora.
Przyczyną może być też innego rodzaju sytuacja na poziomie serwerowym – błąd w konfiguracji domeny, zmiana we wskazaniu domeny na katalog czy wreszcie usterka samego serwera. Jeśli zatem zadajesz sobie pytanie, dlaczego w Google nie ma mojej strony – to zacznij od sprawdzenia, czy Ty widzisz ją poprawnie. Po prostu wpisz adres Twojej strony w przeglądarkę i sprawdź, czy wyświetla się prawidłowo.
5. Błędny kod odpowiedzi HTTP
Każde wejście na Twoją stronę internetową (także odwiedziny robota) powoduje zwrócenie kodu odpowiedzi przez serwer – ten kod świadczy o tym, czy dana witryna może być bez problemu wyświetlona.
Jeśli strona działa bez przeszkód i wyświetla się prawidłowo, serwer zwraca kod odpowiedzi „200” – wtedy robot wyszukiwarki uznaje, że witryna może być bezproblemowo indeksowana.
Jeżeli strona internetowa została przeniesiona i wyświetla się teraz pod innym adresem, pojawia się kod „301” – stanowi to wskazówkę dla robota. Strona była już zaindeksowana w Google, a teraz chcesz ją przenieść na nowy adres? Przygotuj przekierowanie 301.
Istnieją również inne kody, a każdy z nich oznacza, że wystąpił jakiś problem i robot nie zaindeksuje Twojej strony. Oto one:
- 401 Unauthorized Nieautoryzowany dostęp – wystosowane żądanie wymaga uwierzytelnienia, dostęp do zasobu nie jest możliwy
- 403 Forbidden Zabroniony – zastosowana konfiguracja bezpieczeństwa uniemożliwia serwerowi zwrócenie żądanego zasobu
- 404 Not Found Nie znaleziono – według podanego adresu URL zasób nie został odnaleziony przez serwer
- 503 Service Unavailable Usługa niedostępna – zapytanie nie może być zrealizowane przez serwer, gdyż wystąpiło przeciążenie
Ostatni z wymienionych kodów może świadczyć o tym, że Twoja strona została wykonana nieoptymalnie i za bardzo eksploatuje serwer. Być może wymaga serwera o lepszych parametrach, przeniesienia na VPS lub serwer dedykowany. Zazwyczaj jednak w podobnej sytuacji przyczyną, dla której w Google nie ma Twojej strony jest to, że to ona sama stanowi źródło błędów – jest napisana w sposób powodujący zapętlenia i bardzo nieoptymalnie wykorzystuje zasoby.
Często w podobnej sytuacji pomaga włączenie technik cache’owania, jak LS Cache i REDIS. Dzięki temu każde wejście na stronie powoduje wielokrotnie mniejsze obciążenie serwera, ponieważ uruchamia się znacznie mniej procesów. Błąd typu 5xx jest zatem o wiele mniej prawdopodobny.
6. Urządzenia mobilne
Wyszukiwarka Google od kwietnia 2015 roku zwraca szczególną uwagę na to, aby strony internetowe posiadały wersje mobilne. Podczas korzystania z wyszukiwarki na urządzeniu mobilnym, strony nie przystosowane do mobilnego wyświetlania nie pokażą się w wynikach wyszukiwania Google.
Twoja strona nie wyświetla się w Google podczas korzystania z telefonu lub tabletu? Upewnij się, czy wyświetla się poprawnie na komputerze – możliwe, że jest indeksowana prawidłowo, lecz według Google nie jest wystarczająco wartościowa, aby wyświetlała się w wynikach wyszukiwania na urządzeniach mobilnych.
7. Upływ czasu
W wypadku młodych stron ich zaindeksowanie przez Google wymaga po prostu czasu. W kulturze nanosekundy wiele osób spodziewa się, że czas ten będzie krótki, stąd wiele osób zastanawia się: „Kiedy Google zaindeksuje moją stronę?”.
Najpierw trzeba się zastanowić nad pytanie, jak Google wyszukuje strony. Generalnie – istnieją dwa zasadnicze źródła: linki do Twojej strony z innych miejsc, oraz to, co stronie powiesz wyszukiwarce poprzez narzędzie Google Search Console.
Zakładam, że nie chcesz czekać i sprawdzać osobiście, po jakim czasie strona pojawia się w Google „sama”, bo może to oznaczać długie tygodnie. W wypadku nowej strony lepszym pomysłem będzie od razu przypisanie strony do Google Search Console i zgłoszenie prośby o zaindeksowanie poprzez interfejs konsoli. W tym celu wejdź na adres https://search.google.com/ i zgłoś swoją nową witrynę.
Z menu w lewym górnym rogu wybierasz „+Dodaj usługę”, a następnie możesz zdecydować, czy interesuje Cię dodanie całej domeny, czy konkretnego adresu url.
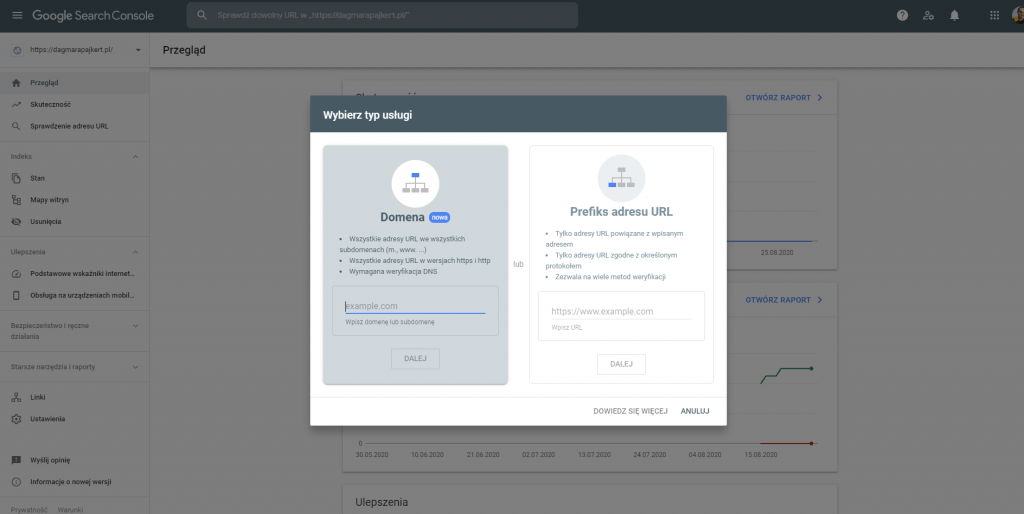
Twoja strona będzie musiała zostać zweryfikowana, robi się to poprzez umieszczenie na serwerze małego pliku weryfikacyjnego, zawierającego zadany przez Google Search Console ciąg znaków, albo poprzez wpis w strefie DNS.
Jak dodać stronę w Google – ważne!
Kiedy w Google nie ma Twojej strony, a strona jest nowa, najlepiej skorzystaj z narzędzia Google Search Console. Tam dodajesz stronę, a nie całą domenę, najlepiej dodaj ją czterokrotnie, tj. w wariancie z wywołaniem po https, po http (czyli z certyfikatem SSL i bez niego), a także z www. i bez tego przedrostka z przodu. Oczywiście zadbaj o to, żeby strona wczytywała się w każdym z tych wariantów i najlepiej zapewnij, że wszystkie na koniec powodują przejście na wersję – moim zdaniem nalepszą, czyli https://domena.pl
Certyfikat SSL naprawdę pomaga. Pomaga w ocenie przez Google, pomaga w budowaniu zaufania ludzi, pomaga w zapewnieniu poufności danych. Dlatego mocno rekomenduję stosowanie szyfrowania transmisji, tym bardziej, że podstawową ochronę certyfikatem Let’s Encrypt możesz mieć całkowicie bezpłatnie.
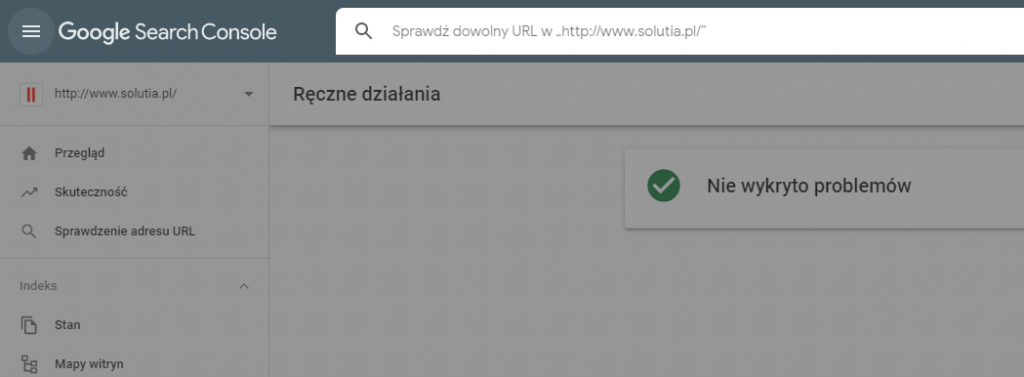
Następnie kliknij „Sprawdzanie adresu url” i po podaniu adresu, który Twoim zdaniem nie jest widoczny w Google, będziesz mógł zgłosić prośbę o ponowne zaindeksowanie.
8. Kary od wyszukiwarki Google
Jeśli w Ocenie wyszukiwarki Twoja strona stosuje praktyki naruszające zasady Google – może się okazać, że Twoja strona zostanie ukarana. Nakładanie kar nie jest zjawiskiem częstym w wypadku „normalnie” prowadzonych stron i działań optymalizacyjnych. Podczas konferencji SEMKRK 12 BIG bardzo ciekawie o zagadnieniu kar opowiadał Kaspar Szymański.
Kto jak kto, ale Kaspar to ogromny autorytet, człowiek który w Google przez lata zajmował się kształtowaniem wyników wyszukiwania. Zdaniem Kaspara kary dotyczą przede wszystkim dwóch obszarów: spamerskiego linkowania do Twojej strony oraz duplikacji treści.
Jeśli Twoja strona zostaje ukarana przez Google, to jedyny sensowny sposób postępowania polega na usunięciu nieprawidłowości. Następnie opisz kroki podjęte, aby je usunąć. Nie ma sensu argumentacja o utraconych dochodach. Nie wygrażaj konsekwencjami prawnymi – serio, ludzie w ten sposób próbują rozmawiać z Google!
Jeśli zatem kara z Google dotyka Ciebie – wyjaśnij krótko, które linki udało Ci się usunąć. Jeśli jakiś się nie udało – opisz dlaczego. Usuń zduplikowane treści i poproś o zdjęcie restrykcji, to wszystko. Pozostaje cierpliwie czekać na reakcję Google, nie jesteś w stanie przyspieszyć tego procesu.
Na pocieszenie powiem Ci, że kary tego rodzaju są stosowane naprawdę rzadko.
Dlaczego w Google nie ma mojej strony – podsumujmy
Przyczyn braku Twojej strony w indeksie Google może być wiele. W uproszczeniu można powiedzieć, że są one zawiązane z etapem życia strony.
Strony młode zazwyczaj po prostu jeszcze nie są zaindeksowane. W tym wypadku konsola Google Search Console może pomóc Ci w diagnozie tej sytuacji.
Strony w średnim wieku często cierpią na błędy konfiguracyjne lub błędy w pliku robots.txt, ewentualnie blokujące metatagi. Te blokady były zakładane podczas tworzenia strony, aby Google nie indeksowało jej zbyt wcześnie. Deweloper strony zapomniał natomiast o zdjęciu blokady po włączeniu strony produkcyjnie.
Strony dojrzałe częściej cierpią z powodu problemów wydajnościowych (błędy 5xx), złej historii (nieprawidłowe przekierowania 301) lub nie dość niezawodnego wyświetlania się.
Do rzadko występujących przyczyn należą kary od Google – na nie po prostu trzeba sobie „zasłużyć”. A jakie jest Twoje doświadczenie z indeksowaniem? Czy spotkała Cię któraś z opisanych przeze mnie sytuacji? Daj znać w komentarzu!



Cenne kompendium wiedzy. Dodam od siebie, że obecnie bardzo ważna jest szybkość działania strony. Należy unikać zbędnych skryptów i stosować nowoczesne formaty grafiki. Konieczność to posiadanie szybkiego hostingu, z szybkim reagowaniem na wszelkie awarie.
Dzięki za opinię!
Plik robots.txt nie blokuje strony przez zaindeksowaniem. Strona się indeksuje tylko w description masz informację, iż dane do tej podstrony zostały zablokowane. Ale jednak się indeksują 🙂
Paweł – dziękuję za merytoryczny komentarz. Na Zgreda zawsze można liczyć!
Blokady w robots.txt zbyt wiele razy nie widziałem. Poza tym Google i tak taką stronę może spokojnie indeksować, chociaż nie będzie rankowała zbyt dobrze 😉 Natomiast widziałem kilkukrotnie wrzucenie na produkcję domeny z tagiem 🙂 Działo się tak zarówno w przypadku nowych stron (i wtedy rozmyślania, czemu jeszcze nie ma jej w Google, skoro stoi już 2 miesiące), jak i w przypadku odświeżenia layoutu dobrze wypozycjonowanej strony (co skutkowało wylotem z indeksu) 🙂 Widziałem też spektakularne upadki, gdy dział IT wymyślał w pewnym momencie, bez konsultacji z SEO-wcem, że nowa wersja witryny będzie oparta w 100% o JS z renderowaniem po stronie klienta.
Jeżeli chodzi o tworzenie strony w JS to ciężko zawsze jest taki twór pozycjonować. Właściwie w dzisiejszych czasach jest to absolutnie bez sensu. Strony musi w obecnych czasach mieć solidny content inaczej to syzyfowa praca.
Tak jest chodzi o kwestię indeksacji lub nie strony, to tag robots tutaj gra pierwszą rolę. Nie chodzi jednak o plik robots.txt ale meta tag robots=””, który należy umieścić w sekcji nagłówkowej podstrony z odpowiednim atrybutem np nofollow, przykładowo robots=”noindex,follow” 🙂 W takim przypadku dana podstrona nie będzie indeksowana, ale roboty wyszukiwarek mogą po niej „chodzić” co jest o tyle dobre, że będą mogły indeksować inne podstrony (za wyjątkiem obecnej), do których linki znajdują się na obecnej.
Bardzo fajnie opisane kompendium wiedzy. W przypadku takich problemów Google Search Console jest niezastąpione.
Dyrektywę noindex można zastosować w dwóch miejscach: w metatagu w sekcji podstrony i w nagłówku odpowiedzi HTTP (X-Robots-Tag: noindex). Pozdrawiam 🙂
To jeszcze raz ja, wybacz. Użyłam znaków wykorzystywanych przez kod HTML i zjadło mi słowo 😛 Miało być: w metatagu w sekcji head podstrony.
Co do wspomnianych stron renderowanych w JavaScript to Google zaczyna sobie co raz lepiej z tym radzić. Co prawda nie zmienia to faktu, że nie tędy droga, jednak technologia wciąż idzie na przód, a co za tym idzie i możliwości Google.
Można by artykuł zaktualizować trochę, w ciągu ostatnich dwóch lat nieco się skomplikowało z indeksacją. No i pojawiło się 'zjawisko’ site 4 :). Pozdrawiam.
Przydałoby się odświeżenie materiału. Polecam wykorzystać tzw. recykling treści 🙂 Szkoda merytorycznych materiałów, które nie są aktualne.
Bardzo ciekawy wpis! Czy możemy liczyć na jakieś odświeżenie?
Hej, niedługo planujemy aktualizację!